
梯度下降优化-RMSProp 1. 问题引入 AdaGrad 的问题: AdaGrad 通过累积所有历史梯度的平方和来自适应调整学习率,但这种方法存在一个严重问题: 学习率衰减过快:随着训练进行,累积梯度平方和 $G_t$ 单调递增,学习率 $\eta / \sqrt{G_t + \epsilon}
 发布于 2026-01-14
发布于 2026-01-14
梯度下降优化-AadGrad自适应梯度 1. 问题引入 在优化复杂的损失函数时,普通的梯度下降法和动量法会遇到以下问题: 固定学习率问题:所有参数使用相同的学习率,但不同参数可能需要不同的更新速度 稀疏梯度问题:某些参数很少更新(梯度稀疏),需要更大的学习率 频繁更新问题:某些参数频繁更新(梯度大)
发布于 2026-01-08
梯度下降优化-Momentum动量法 1. 问题引入 在优化复杂的损失函数时,普通的梯度下降法会遇到以下问题: 收敛速度慢:在平坦区域,梯度很小,更新步长很小 容易陷入鞍点:在鞍点处梯度接近0,算法可能停滞不前 震荡问题:在狭窄山谷中容易来回震荡,收敛慢 学习率敏感:需要精心调整学习率 Moment
发布于 2026-01-07
梯度下降优化-指数移动加权平均 问题描述 原生梯度下降法虽然简单有效,但在面对复杂损失函数时存在以下问题: 收敛速度慢:在平坦区域或梯度较小时,更新步长很小 容易陷入鞍点:在鞍点处梯度接近0,参数无法更新,难以继续优化 震荡问题:在狭窄山谷中容易来回震荡 学习率敏感:需要精心调整学习率
发布于 2026-01-06
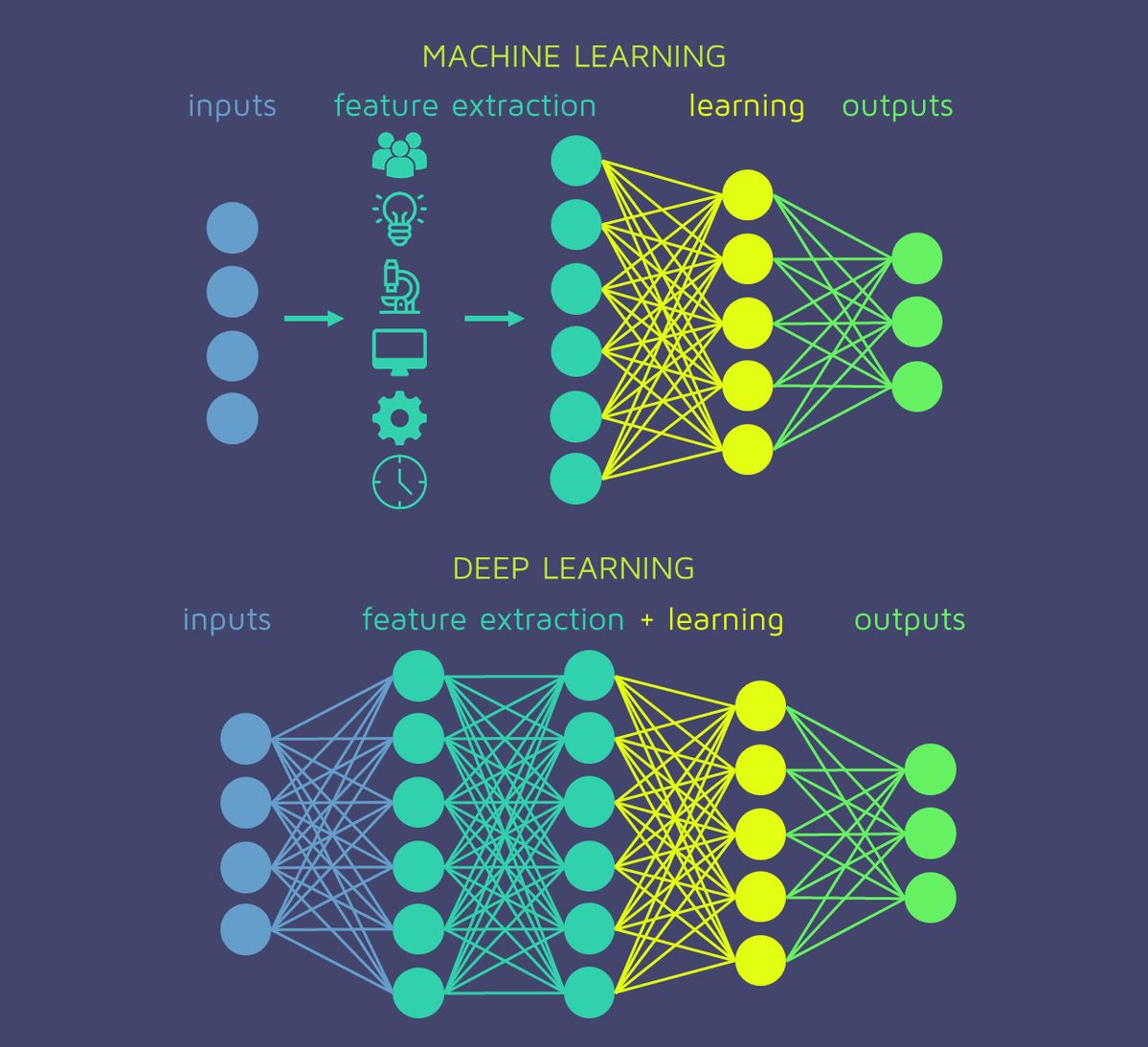
机器学习:分类、回归、聚类 机器学习能够解决的问题主要分为三大类: 分类问题(Classification):预测离散的类别标签 回归问题(Regression):预测连续的数值 聚类问题(Clustering):发现数据的内在结构 这三类问题构成了机器学习的基础,理解它们对于掌握机器学习至关重要。
发布于 2026-01-05
批量、随机、小批量梯度下降法 三种梯度下降方法概述 1. 批量梯度下降(Batch Gradient Descent, BGD) 原理: 使用全部训练样本计算梯度 每次迭代更新参数时,需要遍历所有样本 梯度计算:$\nabla J(\theta) = \frac{1}{m}\sum_{i=1}^{m
发布于 2026-01-05
通过线性模型理解梯度下降 多元线性回归是机器学习中最基础的模型之一,用于预测连续值。我们使用梯度下降法来优化模型参数,找到使损失函数最小的参数值。 为什么需要梯度下降法? 多元线性回归的参数优化问题通常无法直接求解(当特征维度很高时) 梯度下降法是一种通用的迭代优化算法 可以处理大规模数据集 是理解
发布于 2025-12-31
